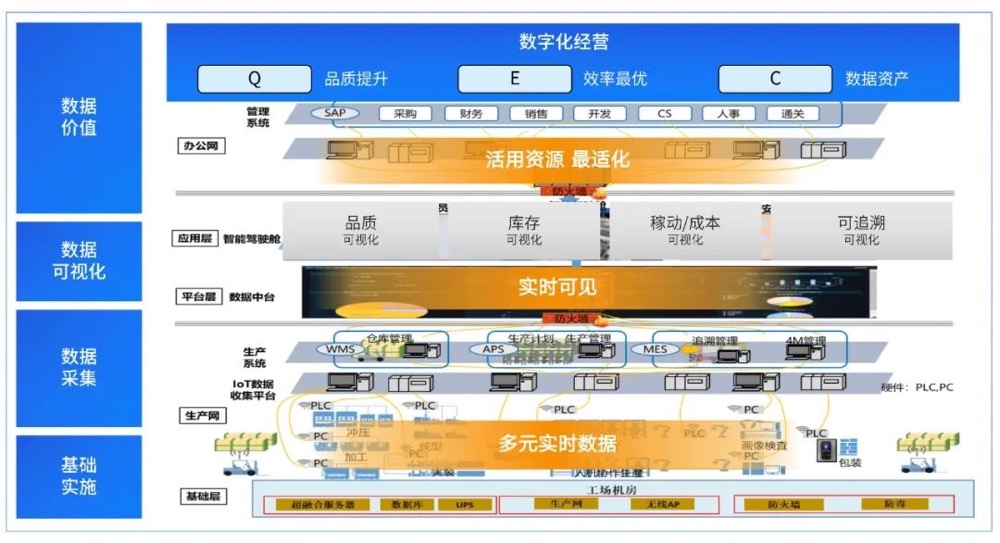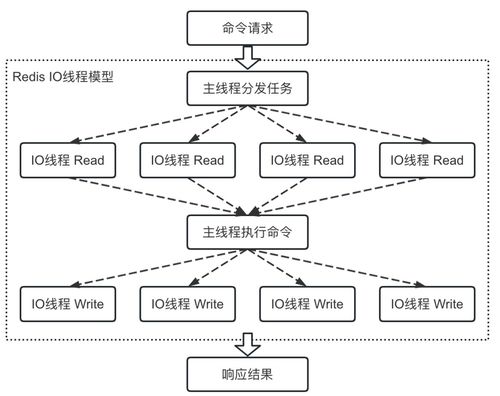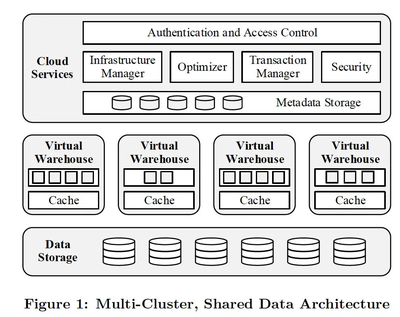
随着云计算技术的发展,云原生数据库已成为现代应用架构的核心组件。尤其在分布式数据库领域,计算与存储分离的设计理念正在重塑数据处理和存储服务的未来。这种架构不仅提升了系统的可扩展性和可靠性,还为企业提供了更灵活、高效的解决方案。
计算与存储分离的基本概念
计算与存储分离是指将数据库的计算层(负责查询处理、事务管理等)与存储层(负责数据持久化和访问)在物理或逻辑上解耦。在传统数据库中,计算和存储通常紧密耦合,导致资源利用率低、扩展困难。而分离架构允许计算节点和存储节点独立扩展,例如,当计算资源不足时,可以单独增加计算节点,而不影响存储层的数据分布。
计算与存储分离的优势
- 弹性扩展:计算和存储资源可以按需独立扩展,避免了传统架构中因耦合带来的资源浪费。企业可以根据业务负载动态调整计算能力,而存储层则根据数据量进行水平扩展。
- 高可用性与容错性:存储层通常采用分布式存储技术,如多副本机制,确保数据持久性和故障恢复。计算节点可以无状态运行,一旦某节点故障,其他节点可快速接管,保证服务连续性。
- 成本优化:分离架构允许使用低成本存储方案(如对象存储),同时计算节点可以基于容器技术实现快速部署和销毁,降低了基础设施成本。
- 性能提升:通过专用存储服务优化数据访问,计算节点可以专注于查询处理,减少I/O瓶颈。结合缓存和分布式索引,显著提升数据处理效率。
数据处理与存储服务的协同
在计算与存储分离的架构中,数据处理和存储服务通过高效协议(如gRPC或自定义RPC)进行通信。计算层负责解析SQL查询、执行事务和优化执行计划,而存储层提供数据读写接口,确保强一致性或最终一致性。例如,在事务处理中,计算节点协调多个存储节点,通过分布式共识算法(如Raft)保证ACID特性。
存储服务通常集成数据压缩、加密和备份功能,而计算层则利用并行处理技术加速复杂查询。这种分工协作使得数据库能够应对海量数据和高并发场景,例如电商平台的秒杀活动或实时分析应用。
实际应用与未来展望
众多云原生数据库,如Amazon Aurora、Google Spanner和TiDB,已成功实践计算与存储分离。它们通过共享存储池和分布式计算框架,实现了跨可用区的灾难恢复和全球数据同步。随着人工智能和边缘计算的兴起,计算与存储分离将进一步演化,支持更智能的数据处理和边缘存储集成。
计算与存储分离作为云原生数据库的“幕后英雄”,不仅推动了数据处理和存储服务的创新,还为企业的数字化转型提供了坚实基础。通过拥抱这一架构,组织可以构建更灵活、可靠的数据平台,应对日益复杂的业务挑战。