在当今大数据时代,元数据管理已成为企业数据治理的核心环节,它帮助组织理解、管理和利用海量数据。Apache Atlas和Metacat作为两种主流的元数据管理工具,在数据处理和存储服务方面各有特色。本文将从数据处理和存储服务的角度,对Atlas和Metacat进行简要分析和比较。
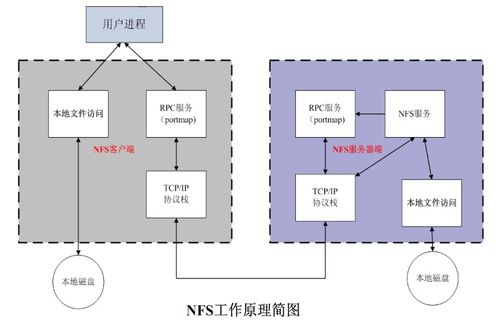
Apache Atlas是一个开源、可扩展的元数据管理和数据治理平台,专为Hadoop生态系统设计。在数据处理方面,Atlas通过预定义的钩子(hooks)自动捕获元数据,例如从Hive、Kafka和Sqoop等组件中提取数据血缘和分类信息。它支持实时元数据更新,并通过REST API允许用户自定义处理逻辑,增强了数据溯源和策略执行的灵活性。存储服务上,Atlas采用图数据库(默认使用JanusGraph)来存储元数据实体和关系,这种结构便于高效查询复杂的数据血缘图。它集成了Apache Kafka用于事件通知,确保元数据变更的可靠传播,但存储层可能面临性能挑战,需要优化图数据库配置。
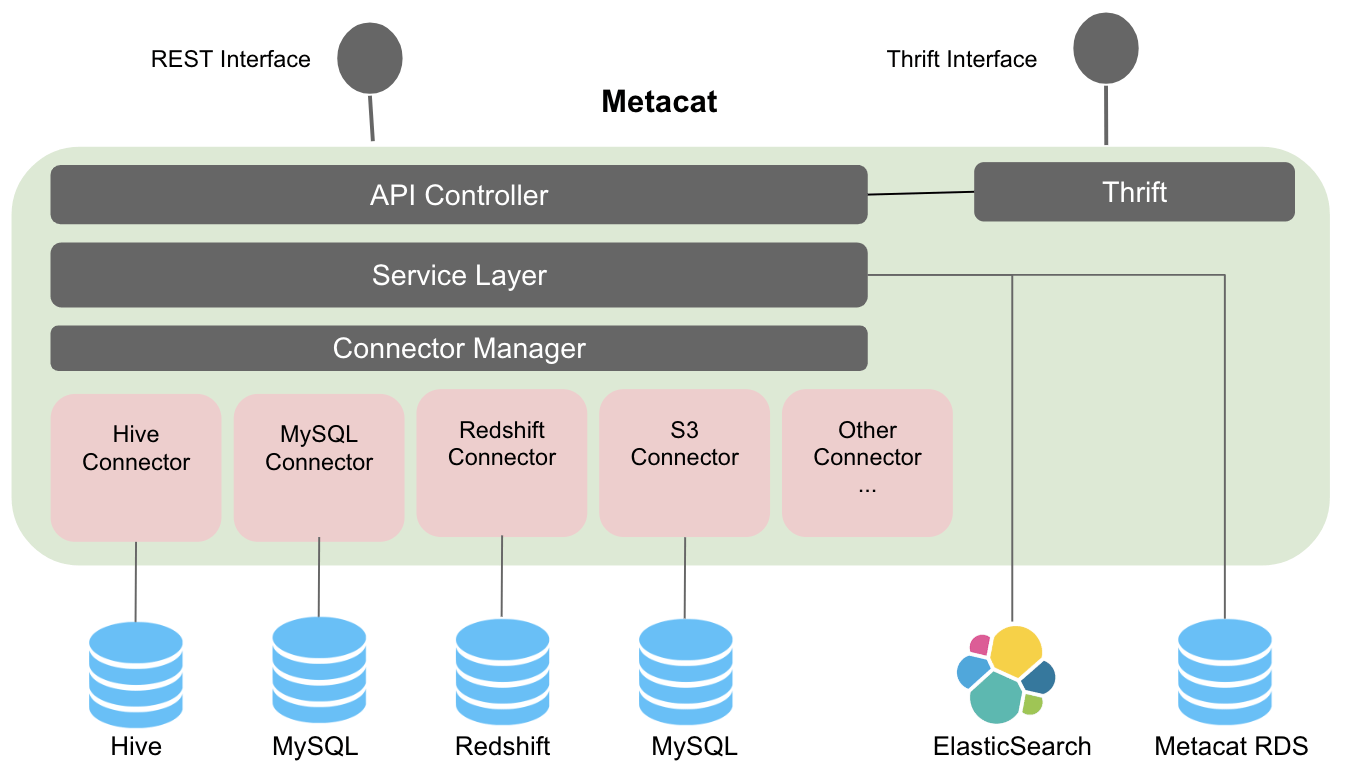
Metacat最初由Netflix开发,后来开源,侧重于解决多数据存储系统的元数据统一管理问题。在数据处理方面,Metacat通过插件化架构支持多种数据源(如Hive、S3、RDBMS),能够集中处理异构元数据,并提供统一的REST接口进行查询和修改。它强调数据发现和访问控制,通过自动分区管理和数据统计收集,提升了数据处理的效率。存储服务上,Metacat使用关系型数据库(如MySQL或PostgreSQL)存储元数据,这种设计简单可靠,易于维护和扩展。它可能不如Atlas在复杂关系查询上灵活,但适合需要稳定、统一元数据视图的场景。
Atlas更适合复杂生态系统下的数据血缘和治理需求,而Metacat则擅长跨数据存储的元数据统一管理。企业在选择时,应根据自身数据处理流程和存储架构来决定:若重视数据血缘和实时治理,Atlas是优选;若追求多源集成和易用性,Metacat更为合适。随着云原生和数据湖的发展,两者都可能进一步优化其处理与存储服务,以支持更广泛的应用场景。