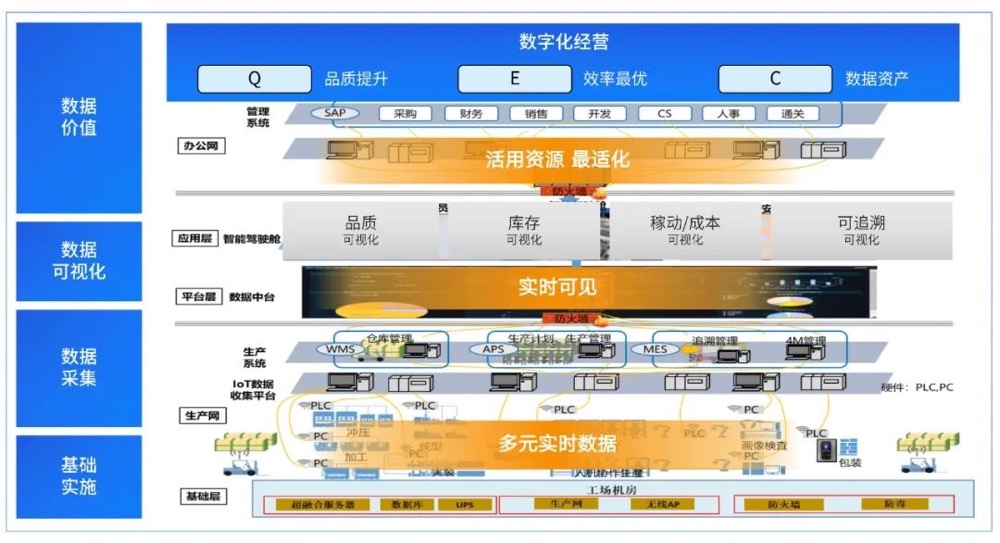
随着大数据处理需求的日益增长,企业对于数据存储与计算服务的灵活性和效率提出了更高的要求。阿里云MaxCompute作为一款领先的云原生大数据计算服务,在数据处理和存储方面展现出强大的能力。本文将重点探讨外部引擎如何直接访问MaxCompute底层存储的开放存储特性,帮助用户实现更高效的数据分析流程。
MaxCompute的开放存储架构
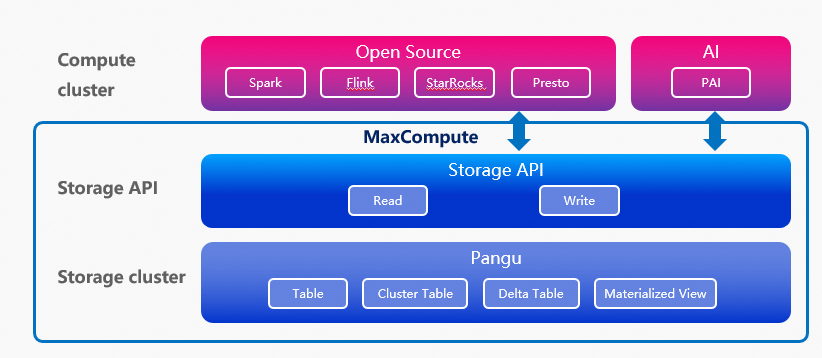
MaxCompute底层存储采用了高度优化的分布式文件系统,支持大规模数据的可靠存储。为了提升数据访问的灵活性,阿里云推出了开放存储功能,允许外部计算引擎(如Spark、Flink等)绕过MaxCompute的计算层,直接与底层存储进行交互。这种设计不仅降低了数据传输的开销,还简化了多引擎协同工作的复杂性。
优势与应用场景
通过外部引擎直接访问MaxCompute存储,用户可以享受到多重优势。它避免了数据搬迁的繁琐过程,减少了存储冗余和网络延迟。这种模式支持实时数据处理,例如,外部流处理引擎可以直接读取MaxCompute存储中的增量数据,实现低延迟的分析。在实际应用中,企业可以将MaxCompute作为统一的数据湖,供不同计算引擎进行查询和分析,从而提高数据利用率和业务响应速度。
实现方式与最佳实践
实现外部引擎访问MaxCompute存储通常涉及以下步骤:通过阿里云提供的API或SDK配置访问权限和安全策略;然后,利用兼容的存储协议(如OSS接口)进行数据读写。为了确保性能,建议优化数据分区和缓存策略,并监控访问日志以识别潜在瓶颈。结合阿里云的其他服务(如DataWorks)可以实现端到端的数据管理,进一步提升效率。
总结
外部引擎直接访问MaxCompute底层存储是云原生大数据服务的重要演进,它打破了传统计算与存储的耦合,赋予用户更多灵活性。作为阿里云数据处理和存储服务的核心组件,MaxCompute的开放存储特性将继续推动企业数字化转型,帮助用户构建高效、可扩展的数据处理架构。随着更多外部引擎的集成,这一功能将释放更大的价值,助力企业在竞争中获得数据驱动的优势。